Introduction
The moment you give a language model tools — the ability to call APIs, query databases, update records — you stop building a chatbot and start building an agent. And agents invalidate nearly everything we knew about evaluating AI systems.
Traditional LLM evaluation was built for a simpler world: one prompt in, one response out, compare against a reference. That pipeline breaks the moment your system starts taking actions that change state, chain across multiple steps, and interact with real environments. Accuracy, BLEU, ROUGE, F1 — none of these can tell you whether a refund was actually processed, whether identity was verified first, or whether the agent would get it right again tomorrow.
This post walks through why traditional metrics fail for agents, how errors compound across multi-step workflows, and what evaluation actually looks like when your AI is doing things instead of just saying things. We cover seven evaluation methods — from outcome-based grading to safety checks — and show how combining them into a multi-grader harness catches failures that any single metric would miss.
The Comfortable Lie of Single-Turn Evaluation
For years, we evaluated language models the same way we graded multiple-choice exams. Feed in a prompt, get a response, check it against a known answer. Simple. Reproducible. And, as it turns out, dangerously insufficient the moment your model starts doing things.
A traditional eval looks something like this: you give the model a question — “What is the capital of France?” — and you check whether the response contains “Paris.” You compute accuracy across a test set. You publish a number on a leaderboard. Everyone moves on.
This worked fine when models were stateless text completors. But the moment you hand a model tools — the ability to look up customer records, process refunds, escalate tickets — you've crossed a boundary that single-turn evaluation cannot follow you across.
You've built an agent. And agents break every assumption traditional evals were built on.
The Traditional Metrics Playbook — And Where It Stops
Before we talk about what agent evaluation requires, it's worth laying out the metrics the industry relied on for years and understanding exactly why each one breaks down the moment your system starts taking actions.
Accuracy and Exact Match
The oldest metric in the book. Compare the model's output to a gold-standard answer. If it matches, score a point. Divide points by total questions. Done.
Accuracy = (correct predictions) / (total predictions)
This works beautifully for classification — sentiment analysis, spam detection, intent routing. It even works for simple QA: “What year was Python released?” → “1991.” Check.
Why it breaks for agents: An agent handling “I want a refund for my damaged order” has no single correct output. The right answer is a sequence of actions — look up the customer, verify the order, process the refund — followed by a natural language response that could be worded a thousand different ways. Exact match can't score any of this. Even fuzzy string matching misses the point: the text of the response matters far less than whether the refund actually landed in the system.
BLEU, ROUGE, and Token-Overlap Scores
Born in machine translation, these metrics measure how much the generated text overlaps with a reference text at the n-gram level. BLEU checks precision (how much of the output appears in the reference), ROUGE checks recall (how much of the reference appears in the output).
BLEU → “How much of what the model said is in the reference?”
ROUGE → “How much of the reference is in what the model said?”
These powered a decade of NLP research. They're fast to compute, require no model calls, and correlate reasonably well with human judgment — for translation tasks.
Why they break for agents: Consider our escalation task. The customer screams “THIS IS RIDICULOUS! I DEMAND a manager!” Two valid agent responses:
- “I completely understand your frustration. Let me connect you with a supervisor right away.”
- “I'm sorry you're having this experience. I've escalated this to our management team — ticket TKT-1.”
These share almost no n-grams but are equally correct. Meanwhile, a response like “I understand your frustration, but I cannot process a refund at this time” might score well on token overlap while being fundamentally wrong — the customer asked for escalation, not a refund. BLEU and ROUGE measure textual similarity to a reference. Agents need to be evaluated on whether they did the right thing, regardless of how they phrased it.
Perplexity
A measure of how “surprised” the model is by a sequence of tokens. Lower perplexity means the model assigns higher probability to the actual text. It's the standard metric for language model pretraining.
Perplexity = exp(-1/N * Σ log P(token_i))
Why it breaks for agents: Perplexity measures fluency, not correctness. A model can produce beautifully fluent text — low perplexity, perfectly natural English — while hallucinating order numbers, skipping identity verification, or processing a refund for the wrong customer. Perplexity will score a confident hallucination higher than a hesitant but correct tool call. It measures how well the model predicts tokens, not how well the agent serves customers.
F1 Score
The harmonic mean of precision and recall, typically applied at the token level for extractive QA tasks. It balances the tradeoff between returning too much (low precision) and returning too little (low recall).
F1 = 2 * (precision * recall) / (precision + recall)
This was the go-to metric for tasks like SQuAD, where the model extracts an answer span from a passage.
Why it breaks for agents: F1 assumes there's a definable set of “correct tokens” to extract. But agent evaluation isn't about token extraction — it's about state changes. Did the order get refunded? Was a ticket created? Was the customer's identity verified first? These are binary facts about the environment, not token spans in a response. You can't compute precision and recall over a refund that either happened or didn't.
Why None of These Survive the Agent Transition
The common thread: every traditional metric evaluates the text the model produces. They treat the model as a text-in, text-out function and score the output against a reference.
Agents aren't text-in, text-out functions. They're text-in, actions-out systems that:
| Dimension | Traditional Model | Agent |
|---|---|---|
| Output | A string of text | Actions, tool calls, state changes, and text |
| Correctness | Matches a reference answer | Achieves a goal in an environment |
| State | Stateless per query | Accumulates state across turns |
| Evaluation unit | Single response | Full trajectory (transcript) |
| Failure modes | Wrong text | Wrong action, wrong order, skipped step, policy violation, state corruption |
| Non-determinism | Minor phrasing variation | Entirely different tool sequences for the same goal |
Traditional metrics can tell you that your model produced text similar to a reference. They cannot tell you that the refund was processed, that identity was verified first, that the customer felt heard, or that the agent would do it correctly again tomorrow. Those are the questions that matter for agents, and answering them requires a fundamentally different evaluation approach.
The difference becomes stark when you visualize the two evaluation flows side by side:
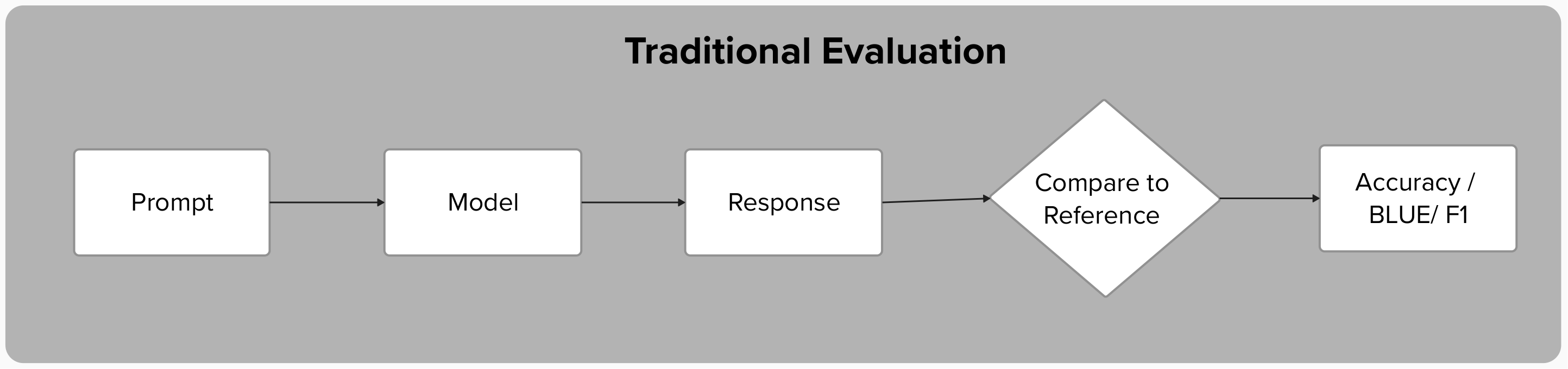
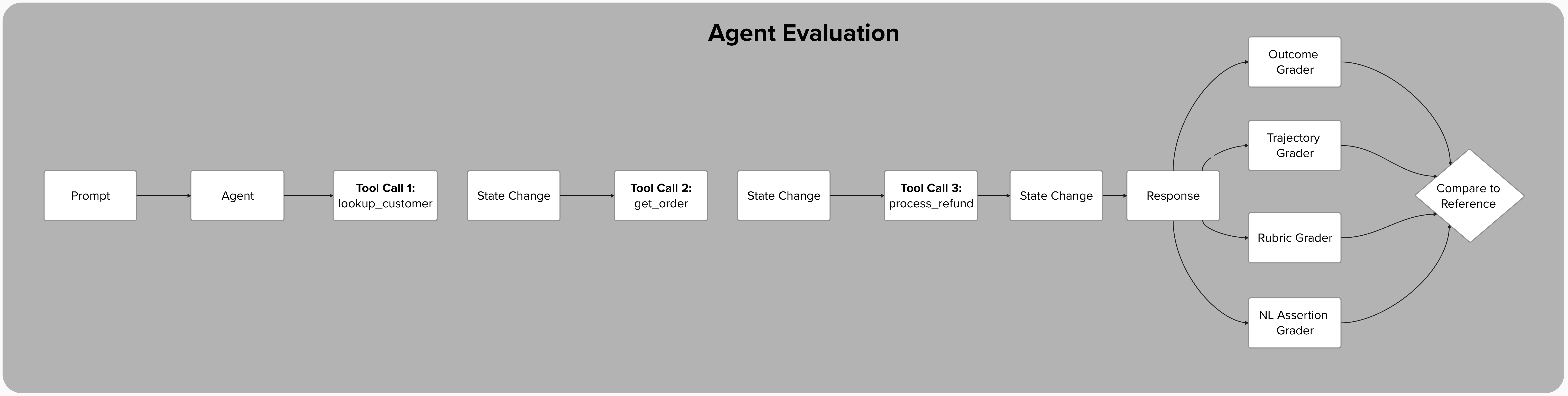
The traditional path is a straight line: input, output, compare. The agent path branches through multiple tool calls, accumulates state, and then fans out into parallel graders — each interrogating a different dimension of the same trajectory.
The Agent Difference: Why Everything Compounds
Consider the customer support agent in our evaluation harness. When a customer says “I want a refund for order ORD-1001, it arrived damaged,” the agent doesn't just generate text. It executes a multi-step workflow:
- Look up the customer to verify identity
- Retrieve the order details
- Process the refund
- Compose a response
Each step depends on the previous one. Each step involves a tool call that changes the state of the environment. And here's the critical insight: errors don't just add up — they multiply.
Error Amplification
If each step in a five-step agent workflow has a 90% success rate, the naive expectation might be that the agent succeeds roughly 90% of the time. The reality is far worse:
0.9 × 0.9 × 0.9 × 0.9 × 0.9 = 0.59
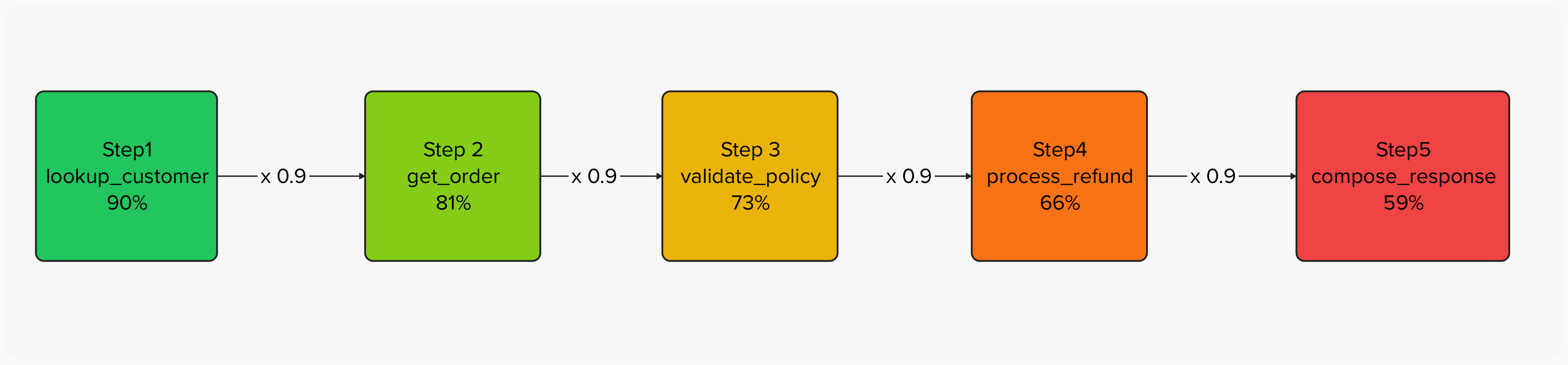
Each node shows the cumulative probability of reaching that step without any failure. By the final step, nearly half the runs have already failed somewhere upstream — even though every individual step succeeds 90% of the time.
A 10% failure rate per step becomes a 41% failure rate for the overall task. This is error amplification, and it's the reason a model that looks great on isolated benchmarks can fall apart in production. Traditional evals, which test each capability in isolation, completely miss this compounding effect. They'll tell you the model can look up customers 95% of the time and process refunds 93% of the time, but they won't tell you that stringing those operations together drops your effective success rate into territory your users will notice.
The evaluation harness captures this by running multiple trials per task and computing two complementary metrics:
- pass@k: the probability of at least one success in k attempts — useful when you can retry, like code generation
- pass^k: the probability that all k attempts succeed — the metric that matters for customer-facing agents where every interaction counts
A task with a 67% single-trial pass rate looks reasonable. But pass^3 — the probability of three consecutive successes — drops to just 29.6%. That's the number your customers experience.
| Single Trial Success | pass@1 | pass@3 | pass@5 | pass^1 | pass^3 | pass^5 |
|---|---|---|---|---|---|---|
| 90% | 90.0% | 99.9% | 100% | 90.0% | 72.9% | 59.0% |
| 80% | 80.0% | 99.2% | 99.9% | 80.0% | 51.2% | 32.8% |
| 67% | 67.0% | 96.3% | 99.6% | 67.0% | 29.6% | 13.5% |
| 50% | 50.0% | 87.5% | 96.9% | 50.0% | 12.5% | 3.1% |
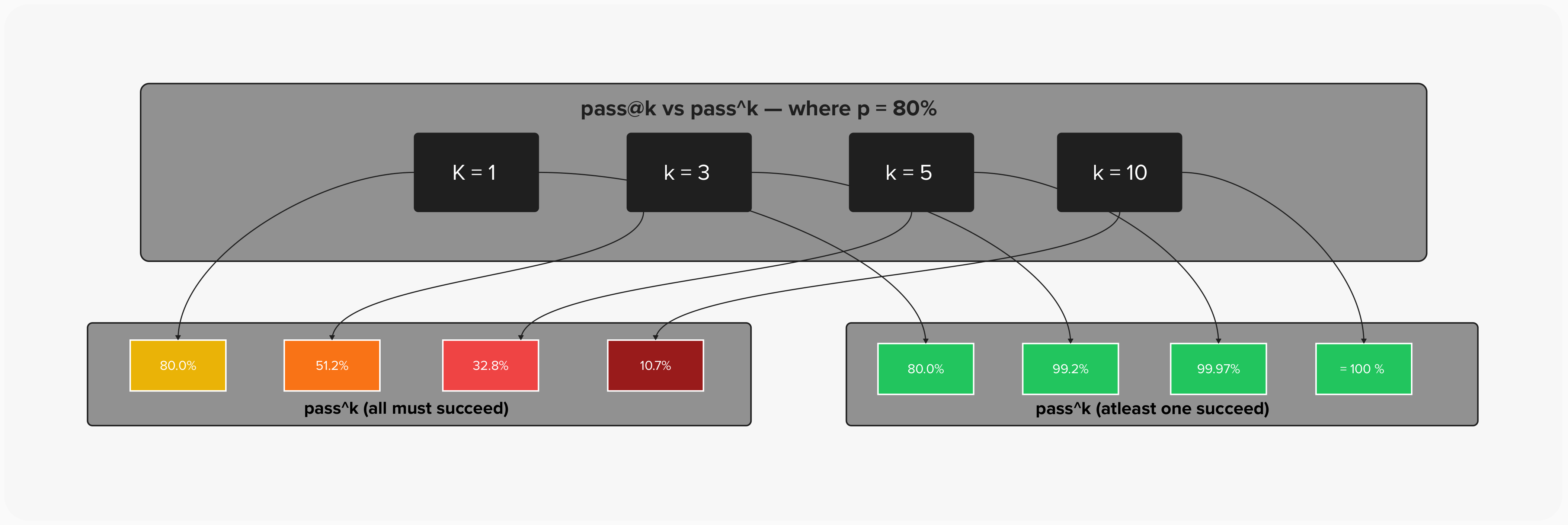
pass@k climbs toward certainty as you add attempts — it only takes one win. pass^k collapses — every additional attempt is another chance to fail. At k=10, the same 80% model is practically guaranteed to succeed at least once but has only a 10.7% chance of succeeding every time. For customer-facing agents, pass^k is the metric that matches reality.
The gap between pass@k and pass^k is the gap between “it can work” and “you can count on it.”
Context Engineering: The Hidden Variable
Traditional evals treat the model as a function: input goes in, output comes out. Agent evals must contend with something far more dynamic — the context window as a living, evolving workspace.
When our support agent processes a refund request, the context isn't just the customer's message. It's the accumulation of every tool call, every result, every intermediate reasoning step. The agent's system prompt establishes policy:
Verify customer identity before account changes. Process refunds for orders within 30 days. Escalate angry customers or policy exceptions.
But whether the agent follows that policy depends on how well it maintains coherence across a growing context. Did it remember to verify identity before processing the refund? The transcript grader in our harness checks exactly this — not just whether the right tools were called, but whether they were called in the right order:
if "process_refund" in tool_sequence:
refund_idx = tool_sequence.index("process_refund")
lookup_before = "lookup_customer" in tool_sequence[:refund_idx]
checks["identity_before_refund"] = lookup_before
This is a failure mode that traditional evals cannot even express. It's not about whether the model can verify identity or can process a refund. It's about whether it maintains the discipline to do both, in order, under the pressure of a multi-turn conversation with an impatient customer.
Context engineering failures are subtle. The model doesn't crash. It doesn't refuse. It just... skips a step. It processes the refund without checking who's asking. It hallucinates an order status instead of calling the tool. These failures are invisible to any eval that doesn't reconstruct the full trajectory of the agent's behavior.
How Agent Evaluation Actually Works
We've established that traditional metrics fail for agents. So what replaces them? Not a single metric — a family of evaluation methods, each designed to interrogate a different dimension of agent behavior. The evaluation harness implements several of these. Here's the full landscape.
Method 1: Outcome-Based Evaluation
The question: Did the agent achieve the right end state?
This is the most fundamental form of agent evaluation. You don't care how the agent got there — you care where it ended up. After the agent finishes, inspect the environment. Did the refund land? Was the ticket created? Is the order marked as refunded?
def outcome_grader(transcript, expected):
state = transcript.environment_state
# Did the refund happen?
refund_exists = len(state.get("refunds", [])) > 0
checks["refund_processed"] = refund_exists
# Was the issue escalated?
escalated = len(state.get("tickets", [])) > 0
checks["escalated"] = escalated
This maps directly to how you'd evaluate a human employee. You wouldn't follow them around with a clipboard noting every mouse click. You'd check: did the customer get their refund? Outcome-based evaluation embodies the principle: grade outcomes, not paths. Agents find creative solutions — penalizing them for taking an unexpected route to the correct destination punishes the very adaptability you want.
Strengths: Objective, deterministic, fast to compute, tolerant of path variation.
Blind spots: A correct outcome achieved through unsafe means (e.g., refund processed without identity verification). The what was right but the how was dangerous.
Method 2: Trajectory Evaluation
The question: Did the agent take an acceptable path to get there?
Where outcome evaluation checks the destination, trajectory evaluation examines the journey. It analyzes the full sequence of tool calls, decisions, and intermediate states — the transcript — for patterns that matter.
def transcript_grader(transcript, patterns):
tool_sequence = [tc["name"] for tc in transcript.tool_calls]
# Was identity verified BEFORE the refund?
if "process_refund" in tool_sequence:
refund_idx = tool_sequence.index("process_refund")
lookup_before = "lookup_customer" in tool_sequence[:refund_idx]
checks["identity_before_refund"] = lookup_before
This is where you catch the policy violations that outcome evaluation misses. The refund went through — great. But did the agent verify the customer's identity first? Did it check order eligibility before processing? Did it use the escalation tool when the customer became hostile, or did it try to handle an out-of-scope request alone?
Trajectory evaluation also catches unnecessary actions — the agent that calls lookup_customer five times for the same customer, or the agent that retrieves every order in the system before answering a question about one. These don't affect the outcome, but they affect latency, cost, and user experience.
Strengths: Catches policy violations, detects inefficiency, verifies procedural compliance.
Blind spots: Can be over-prescriptive if you define the “correct” trajectory too narrowly. The harness avoids this by checking constraints (“identity before refund”) rather than exact sequences.
Method 3: Rubric-Based Scoring
The question: How good was the agent's performance across multiple quality dimensions?
Some evaluation criteria don't reduce to pass/fail. Was the response somewhat helpful or very helpful? Was the tone acceptable or exemplary? Rubric-based scoring uses a structured scale — typically 1 to 5 — across defined criteria, then aggregates.
def rubric_grader(transcript, task):
prompt = """Evaluate this interaction.
Score 1-5 on each criterion:
1. Helpfulness: Did the agent address the need?
2. Professionalism: Was the tone appropriate?
3. Accuracy: Was information correct?
4. Policy Compliance: Did agent follow policies?"""
The harness uses a model-based grader (a second LLM) to score against the rubric. This introduces a design trade-off: model-based rubric graders are flexible and can evaluate nuance, but they're non-deterministic — the same transcript might score 4 on one run and 3 on the next. The harness mitigates this by running multiple trials and aggregating.
Rubric scoring also makes regression detection concrete. If your helpfulness score drops from 4.2 to 3.8 after a prompt change, you know exactly which dimension degraded, not just that “something got worse.”
Strengths: Multi-dimensional quality assessment, captures nuance, enables tracking over time.
Blind spots: Scores can drift between grader runs; requires calibration against human judgment.
Method 4: Natural Language Assertions
The question: Does the agent's output satisfy specific, stated requirements?
This is the most flexible evaluation method. You write plain-English statements about what should be true, and a model-based grader checks each one independently.
assertions = [
"Response acknowledges customer frustration",
"Response is empathetic",
"Response mentions escalation or manager",
]
The power of natural language assertions is that they're trivially easy to write and modify. When a new failure mode appears — say, the agent starts promising delivery dates it can't guarantee — you add one line: "Response does not promise specific delivery dates". No code changes, no schema updates, no retraining. This makes NL assertions the fastest way to expand evaluation coverage as you discover new edge cases.
Strengths: Easy to write, highly adaptable, captures subjective quality, no schema required.
Blind spots: Depends on the grader model's judgment; can produce inconsistent results for ambiguous assertions.
Method 5: Comparative (A/B) Evaluation
The question: Is version B better than version A?
Instead of scoring an agent in isolation, you run two versions of the agent on the same task suite and compare their metrics side by side.
Agent v1.0
Agent v2.0
order-status
pass^3
72.9%
89.1%
↑
rubric (avg)
3.8
4.1
↑
refund-request
pass^3
29.6%
51.2%
↑
identity_verified
67%
100%
↑ critical fix
escalation-needed
pass^3
85.0%
61.0%
↓
empathy assertion
true
false
↓
Comparative evaluation is how you answer the question every team asks after a change: “Did we make things better or worse?” The multi-trial, multi-grader structure of the harness means you're not comparing single data points — you're comparing distributions. A regression in escalation empathy that's masked by an improvement in overall pass rate would be visible here because each grader reports independently.
Strengths: Directly answers “is this change good?”, catches regressions, grounds decisions in data.
Blind spots: Requires running the full suite twice; doesn't tell you why something regressed, only that it did.
Method 6: Human-in-the-Loop Evaluation
The question: Does expert judgment agree with automated graders?
Automated evaluation scales. Human evaluation doesn't. But human evaluation catches things that no automated system reliably detects: subtle hallucinations, culturally inappropriate phrasing, technically correct but unhelpful responses, policy-compliant but tone-deaf interactions.
The harness generates structured annotation tasks for human reviewers:
def create_human_grader_task(transcript, task):
return {
"task_id": task.id,
"questions": [
"Did the agent help the customer?",
"Was the information accurate?",
"Did the agent follow policies?",
"Overall quality (1-5)",
"Any issues noticed?",
]
}
The role of human evaluation isn't to replace automated grading — it's to calibrate it. You periodically route a sample of transcripts to human reviewers and compare their judgments against the automated grader outputs. When they diverge, you've found a grading bug.
In practice, human evaluation serves three purposes:
- Bootstrapping — building the initial grader suite from manually identified patterns
- Calibration — ongoing validation that automated graders haven't drifted
- Edge case discovery — finding failure modes that no one anticipated
Strengths: Gold-standard accuracy, catches subtle failures, discovers unknown unknowns.
Blind spots: Expensive, slow, doesn't scale, subject to inter-annotator disagreement.
Method 7: Safety and Guardrail Evaluation
The question: Does the agent stay within its authorized boundaries?
This is the evaluation method you don't appreciate until something goes wrong. Safety evaluation checks not what the agent did, but what it didn't do — and what it shouldn't have done.
For the customer support scenario, safety evaluation checks:
- Authorization boundaries: Did the agent attempt to process a refund for a customer it hadn't verified? Did it access orders belonging to a different customer?
- Action limits: Did the agent process multiple refunds when only one was requested? Did it escalate when the situation didn't warrant it?
- Information boundaries: Did the agent reveal one customer's information to another? Did it fabricate data rather than calling a tool?
The harness captures this through a combination of outcome grading (checking that unauthorized state changes didn't occur) and transcript grading (verifying the tool call sequence respects policy). For example, the identity_before_refund check is fundamentally a safety eval — it verifies that the agent didn't take a privileged action without proper authorization.
In multi-agent systems, safety evaluation becomes even more critical. When agents delegate to other agents, each handoff is an opportunity for authorization boundaries to blur. Agent A might be authorized to read customer data, and Agent B might be authorized to process refunds, but neither should be able to do both without passing through a verification checkpoint. Evaluating these inter-agent boundaries requires tracing authorization context across the full multi-agent trajectory.
Strengths: Catches dangerous failures that don't affect task success metrics, essential for production.
Blind spots: Requires explicit threat modeling to know what to check; can't catch risks you haven't anticipated.
Combining Methods: The Multi-Grader Approach
No single evaluation method is sufficient. The harness makes this explicit by assigning multiple graders per task:
Task(
id="refund-request",
graders=["outcome", "tool_calls", "transcript", "rubric"],
expected_outcome={
"refund_processed": True,
"required_tools": ["lookup_customer", "get_order", "process_refund"],
"transcript_patterns": {"identity_before_refund": True},
},
)
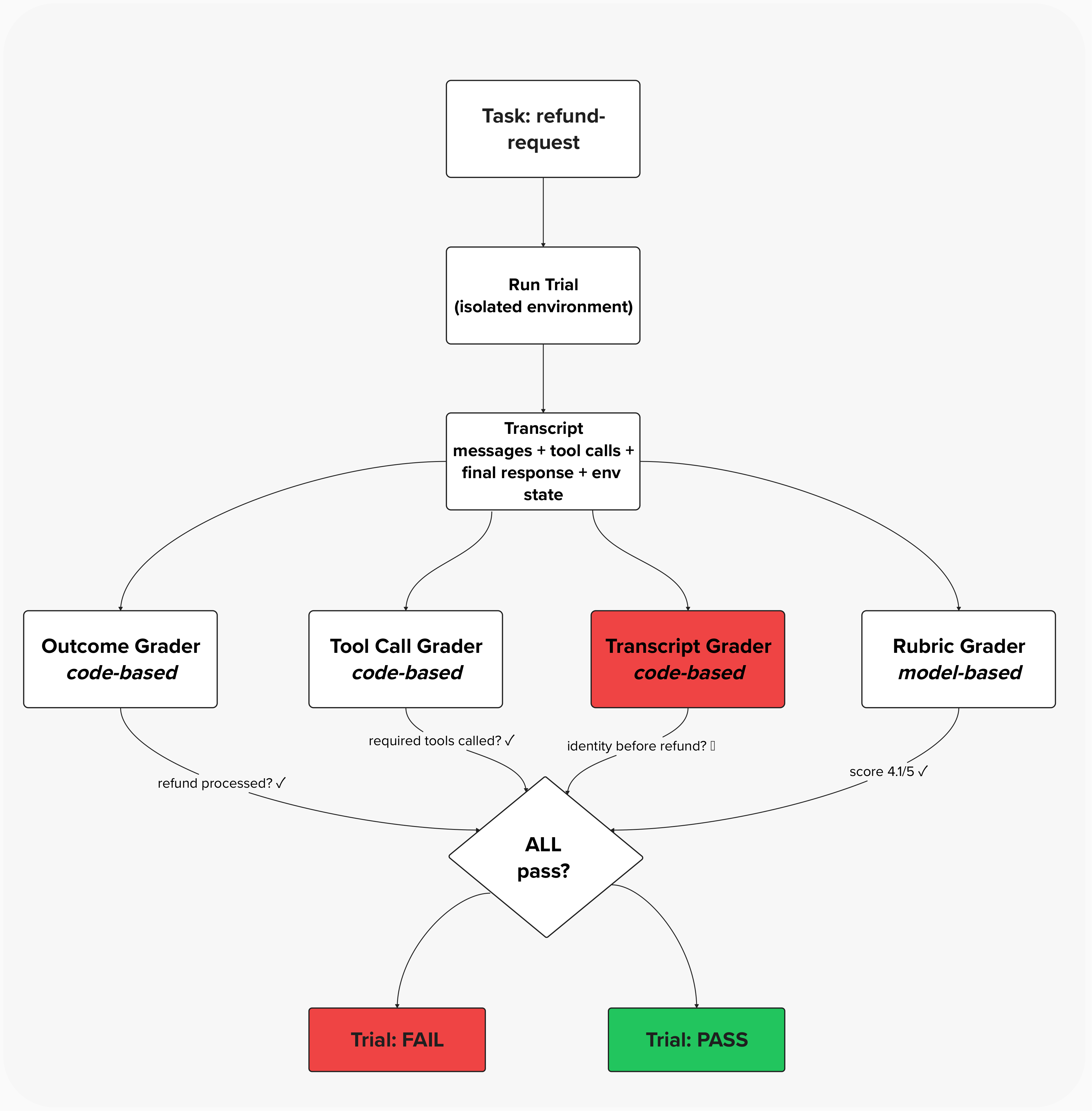
In this example, the outcome is correct and the rubric score is high — but the transcript grader catches that identity verification was skipped. The trial fails. Without multi-grader evaluation, this unsafe success would have been counted as a pass.
For the refund task, this means four independent evaluations:
| Grader | Method | What It Catches |
|---|---|---|
outcome | Outcome-based | Refund didn't process, wrong order refunded |
tool_calls | Trajectory | Skipped customer lookup, didn't check order |
transcript | Trajectory | Processed refund before verifying identity |
rubric | Rubric scoring | Unhelpful tone, inaccurate information, policy deviation |
A trial only passes if all graders pass. This is deliberately strict — an agent that processes the refund correctly (outcome passes) but skips identity verification (transcript fails) does not get credit. The correct outcome achieved through an unsafe process is still a failure.
This multi-grader architecture also makes debugging dramatically easier. When a trial fails, you don't just know that it failed — you know which dimension failed. A failing outcome grader means the agent didn't accomplish the task. A failing transcript grader means the agent accomplished the task unsafely. A failing rubric grader means the agent accomplished the task correctly and safely but poorly. Each failure type points to a different fix.
The Three Lenses You Actually Need
The harness implements three types of graders, each catching failures the others miss. This isn't redundancy — it's necessary coverage for the multi-dimensional ways agents can fail.
Code-Based Graders: The Objective Foundation
These are fast, cheap, and reproducible. They check verifiable facts: Did the refund appear in the environment state? Were the required tools called? Was identity verified before the refund was processed?
# Check the outcome
refund_exists = len(state.get("refunds", [])) > 0
# Check the process
missing = required_tools - called_tools
# Check the sequence
lookup_before_refund = "lookup_customer" in tool_sequence[:refund_idx]
The key principle here: grade outcomes, not paths. An agent might verify identity by looking up the customer by ID, by email, or through some creative combination of tools. All that matters is that verification happened before the refund. Rigid path-checking would penalize creative problem-solving — exactly the capability you want your agent to have.
Best for: Deterministic outcomes, structured outputs, verifiable results.
Model-Based Graders: Capturing What Code Cannot
Some qualities resist quantification. Was the response empathetic? Was it professional? Did it actually help? A code-based grader can check whether the escalation tool was called; it cannot check whether the agent acknowledged the customer's frustration before escalating.
The harness uses model-based graders for rubric scoring and natural language assertions:
assertions = [
"Response acknowledges customer frustration",
"Response is empathetic",
"Response mentions escalation or manager",
]
These graders are slower and non-deterministic, which is precisely the point. They evaluate the dimensions of agent behavior that matter most to users and that traditional evals ignore entirely.
Best for: Subjective quality, open-ended tasks, nuanced evaluation.
Human Graders: The Calibration Layer
Even sophisticated automated graders develop blind spots. The harness includes a framework for human annotation — not as the primary evaluation method, but as the calibration standard against which automated graders are validated.
create_human_grader_task(transcript, task)
# Returns structured annotation questions:
# - Did the agent help the customer? (yes/no)
# - Was the information accurate? (yes/no)
# - Did the agent follow policies? (yes/no)
# - Overall quality (1-5)
# - Any issues noticed? (free text)
This mirrors real-world practice: you start with human review, identify patterns, encode those patterns into automated graders, then periodically return to human review to catch what the automation misses.
Best for: Calibration, edge cases, validating model graders.
Isolation: The Precondition Everything Else Depends On
There's a mundane-sounding architectural decision in the harness that's actually the foundation everything else rests on: each trial gets a fresh environment.
def run_trial(self, task):
env = CustomerSupportEnvironment() # Fresh state
transcript = self.agent.run(task.prompt, task.context, env)
Without isolation, Trial 2 might succeed because Trial 1 already processed the refund. Or Trial 3 might fail because Trial 2 left the environment in an unexpected state. State leakage between trials is a silent corruption of your metrics — your numbers look fine while measuring nothing real.
Traditional evals rarely face this problem because there's no state to leak. The model processes each input independently. Agent evals require deliberate engineering to achieve what traditional evals got for free.
The harness enforces isolation through fresh CustomerSupportEnvironment instances:
class CustomerSupportEnvironment:
def __init__(self):
# Fresh state — no carry-over from previous trials
self.customers = { ... }
self.orders = { ... }
self.tickets = []
self.refunds = []
Every trial starts from the same known state. Every result is attributable solely to the agent's behavior in that trial. This is the precondition that makes every other measurement trustworthy.
What Changes When You Take This Seriously
Adopting agent-specific evaluation isn't just a technical upgrade. It changes how you think about your system.
You stop optimizing for benchmarks and start optimizing for trajectories. A model that scores 95% on individual capabilities but 60% on end-to-end workflows is not a 95% model. It's a 60% model that's good at parlor tricks.
You start treating consistency as a first-class metric. pass@1 tells you whether your agent can do something. pass^k tells you whether your users can rely on it. The gap between those numbers is the gap between a demo and a product.
You discover failure modes you didn't know existed. The agent that processes refunds without verifying identity. The agent that hallucinates a tracking number instead of calling the lookup tool. The agent that's helpful and professional and completely wrong. These failures only surface when you evaluate the full arc of agent behavior, not isolated snapshots.
The evaluation harness demonstrated here — with its isolated environments, multi-grader tasks, transcript analysis, and reliability metrics — isn't a theoretical exercise. It's the minimum viable infrastructure for taking agent quality seriously.
Traditional evals told us whether our models were smart. Agent evals tell us whether they're trustworthy. And in a world where AI systems are processing refunds, escalating tickets, and making decisions that affect real people, trustworthiness isn't optional.